

无论是整理学习资料还是剪辑视频素材,从视频文件中提取音频轨道都是一个高频需求。本文将从底层原理出发,结合真实场景,介绍一套完整的视频音频提取方案。

一、为什么需要”解封装”而非”翻录”
很多用户初次接触音频提取时,会尝试用手机外放再录音的方式获取音频。这种方式存在两个明显问题:
- 音质损失:环境噪音无法避免,二次编码导致音质劣化
- 效率低下:无法批量处理,需要逐条手动操作
正确的技术路径是解封装(Demuxing)——直接从视频容器(如 MP4、MKV、MOV)中分离出音频轨道,不涉及重新编码,因此能做到:
- 零音质损失(与源视频音频完全一致)
- 支持批量自动化处理
- 可自由选择输出格式与参数
二、典型应用场景与需求拆解
| 用户类型 | 核心需求 | 技术要点 |
| 自媒体剪辑师 | 从多部电影/素材截取对白和配乐 | 批量提取、无损格式、声道可选 |
| 考研党/网课学习者 | 视频课程转音频,通勤时”听”课 | 小体积、人声清晰、省流量 |
| 播客制作人 | 从采访视频中分离人声,导入后期软件 | 剪辑软件兼容格式(WAV)、高码率 |
| 家庭用户 | 保留孩子表演/宠物视频的声音纪念 | 操作简单、音质不压缩 |
这些需求的本质相同:从视频文件中快速、高质量地获取音频轨道。
三、功能演示:嗨格式音频转换器
以下以嗨格式音频转换器为例,演示从视频到音频的完整操作。
移动端操作演示
Step 1:进入音频提取功能
打开应用,在首页选择「音频提取」入口。
![]()
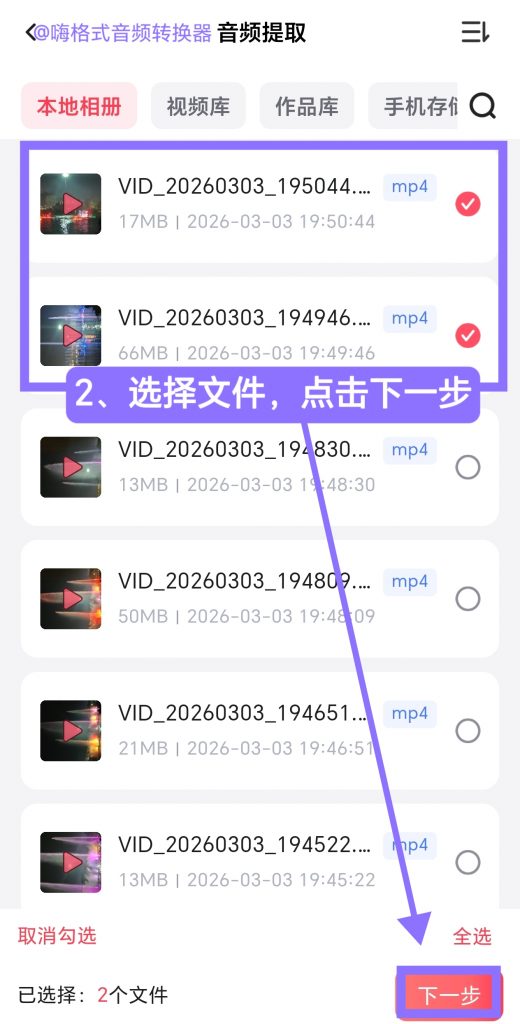
Step 2: 从本地相册等渠道选择文件(支持多选、全选),点击“下一步”。
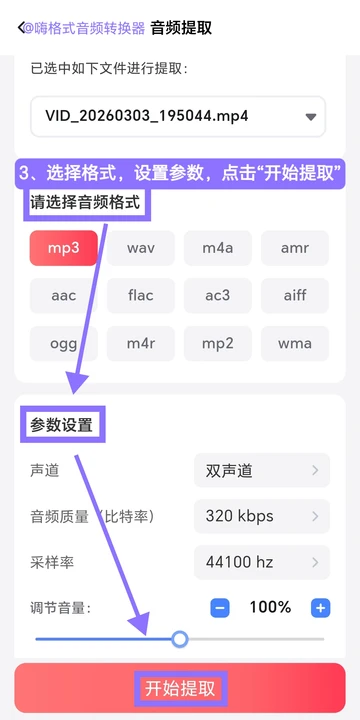
Step 3:按场景配置输出参数
根据使用目的选择格式与质量:
| 使用场景 | 推荐格式 | 比特率 | 声道 | 说明 |
| 通勤听课/播客 | M4A | 128kbps | 单声道 | 体积小,人声清晰度足够 |
| 音乐 MV 转音频 | MP3 | 256kbps | 立体声 | 兼顾音质与设备兼容性 |
| 后期专业剪辑 | WAV | 自动(无损) | 原声道 | 无压缩,保留全部细节 |
| 制作 iPhone 铃声 | M4R | 192kbps | 立体声 | 苹果设备原生支持 |
避坑提示:仅用于听课、会议录音时,无需选择 WAV 或高码率 MP3。128kbps 单声道 M4A 的文件体积约为无损 WAV 的 1/10,而人声清晰度几乎无差别。
Step 4:执行提取并管理文件
点击「开始提取」,完成后可在「作品库」中试听、重命名、保存到本地或分享至微信。
电脑端操作演示
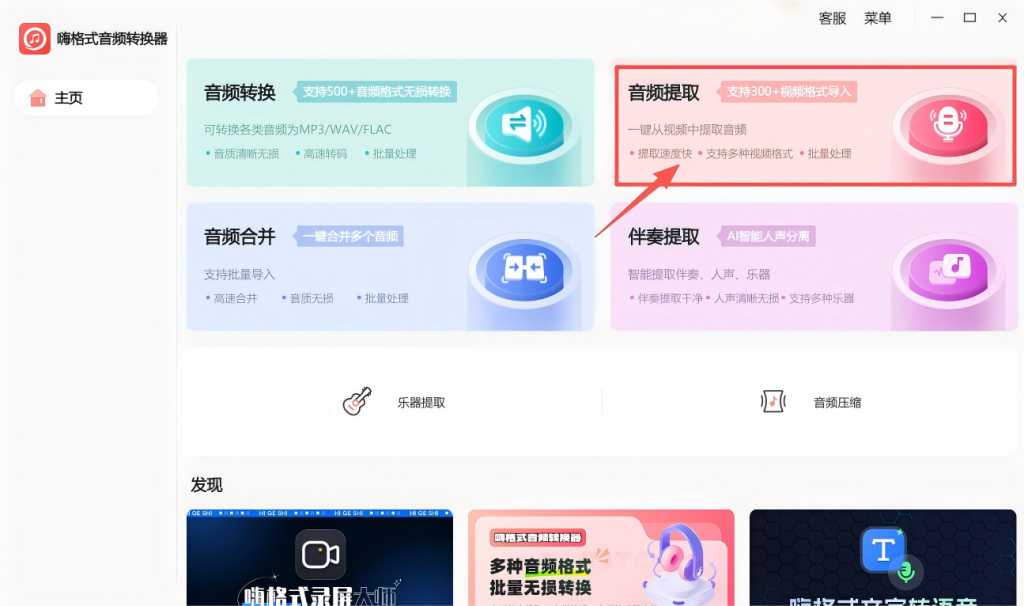
Step 1:进入功能模块
打开软件,首页选择「音频提取」。
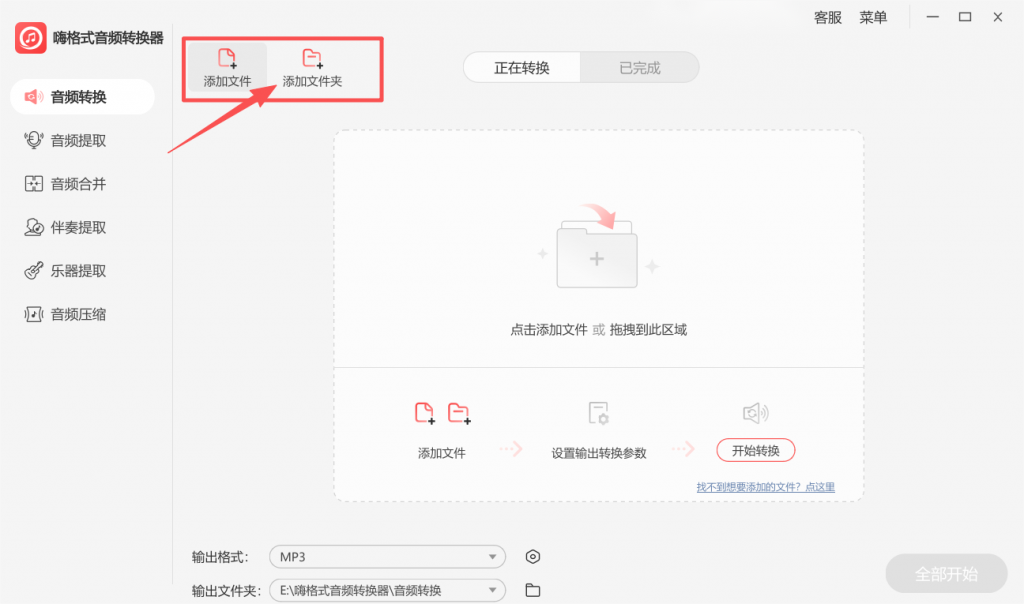
Step 2:批量导入视频
点击「添加文件」,支持一次性拖入多个视频文件,也可通过文件夹批量导入。
Step 3:统一或差异化设置输出参数
- 若所有视频需要相同输出格式 → 底部统一设置,效率最高
- 若不同视频需要不同格式 → 逐个单独配置
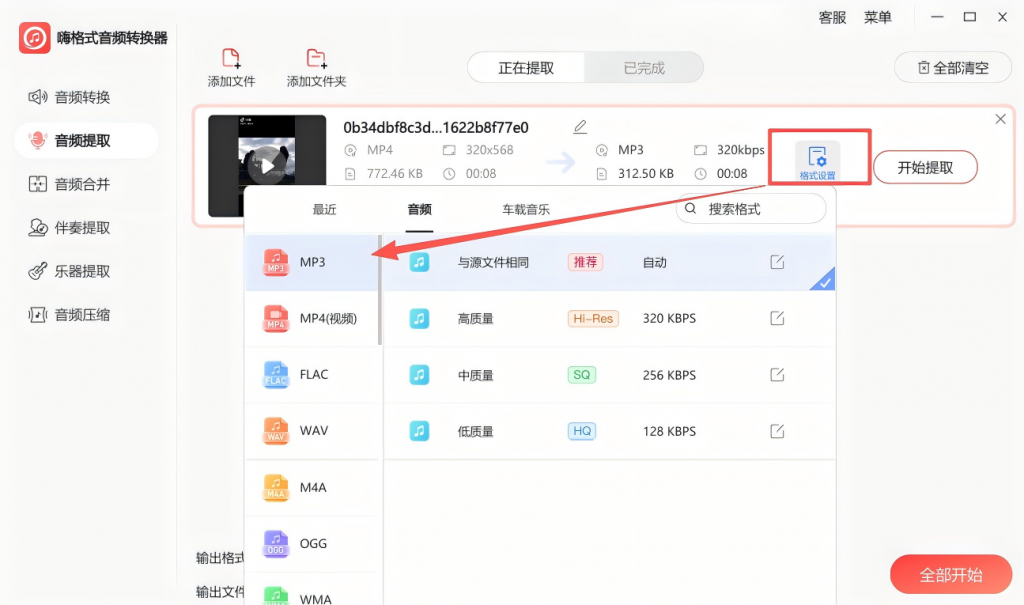
Step 4:执行提取与结果管理
点击「开始提取」,完成后在「已完成」界面可按时间排序,批量打开文件所在文件夹。
四、进阶场景:提取不是终点
场景一:只保留人声,去除背景音乐
普通音频提取会保留原始音轨中的所有内容(人声+伴奏混音)。如需分离人声,应使用AI 人声分离功能,通过深度学习模型将人声与伴奏轨道分离,效果接近专业分轨软件。
场景二:原视频音质本身较差
解封装提取无法改变源素材质量。若原视频经多次压缩(如微信转发后的语音条),提取后的音质同样受限。此时需借助音频修复/增强工具,而非单纯提取。
场景三:保留元数据信息
部分场景需要保留时间戳、章节标记等信息。支持在提取过程中编辑并写入音频文件的元数据(Metadata),便于后续归档管理。
五、常见问题
Q:提取后的音频会有杂音吗?
A:不会。解封装提取是”拷贝”音频轨道,不重新编码,不会引入新噪音。若提取结果有杂音,说明源视频本身存在该问题。
Q:支持批量提取吗?一次最多处理多少个?
A:支持。电脑端可一次性导入数十个视频,手机端支持多选和全选。实际处理数量取决于设备存储空间与性能。
Q:提取后的音频能直接发送微信吗?
A:可以。MP3 和 M4A 格式均被微信支持,可直接发送和预览。
Q:提取的音质与直接用耳机听视频有区别吗?
A:没有区别。二者调用的是同一份音频数据,解封装过程无损耗。
六、总结
视频提取音频的核心在于选择正确的技术路径——解封装提取优于翻录转录,批量处理优于逐条操作,场景化参数配置优于一刀切设置。
无论是截取网课讲解、分离采访人声,还是整理家庭影像的声音记忆,理解底层原理并匹配适合的工具参数,都能在保障音质的前提下大幅提升效率。



