

AI翻唱在2026年已成为内容创作的常规工具,但从原曲到可用干声,中间的人声分离环节仍是大多数创作者的实际瓶颈。本文将从原理到实操,提供一套完整的干声提取解决方案,并演示如何通过智能音频工具高效完成。

一、为什么干声质量决定AI翻唱上限
AI翻唱的核心逻辑是让模型学习你的音色特征,再将其映射到目标歌曲的旋律上。输入的”干声”(去除伴奏、和声、混响后的纯净人声)越干净,模型学到的”你”就越真实。
常见的问题: 分离不彻底导致伴奏残留、和声与人声粘连、高频齿音被误删。这些瑕疵进入训练流程后,模型会把噪音当成你的音色特征,最终翻唱自带”塑料感”。
二、人声分离的两种技术方案
方案一:AI智能分离:嗨格式音频转换器(适合大多数创作者)
针对上述痛点,当前主流音频处理工具已提供从原曲到干声的完整捷径。以嗨格式音频转换器为例,它将复杂的分离算法封装为四个专用AI模型,用户只需根据最终用途对号入座,无需理解背后的技术细节。
四个AI模型及适用场景:
| 模型 | 特点 | 适用场景 |
| 模型一 | 人声处理好,速度快 | 快速试音、日常翻唱等效率优先场景,数秒内完成分离,保留主唱基本轮廓 |
| 模型二 | 伴奏处理好,速度快 | 需要纯伴奏(K歌伴奏等),注意此模型用于伴奏提取而非人声分离 |
| 模型三 | 质量高,速度慢 | 音质要求极高的专业场景,如RVC模型训练。保留更多气声、齿音和呼吸细节,这些正是模型学习”真人感”的关键素材 |
| 模型四 | 适合乐器处理 | 分离鼓声、贝斯等乐器轨,用于编曲采样或制作无鼓/无贝斯练习版本 |
移动端操作演示:
step 1.打开APP,首页进入”AI智能工具”板块,选择”提取人声”功能
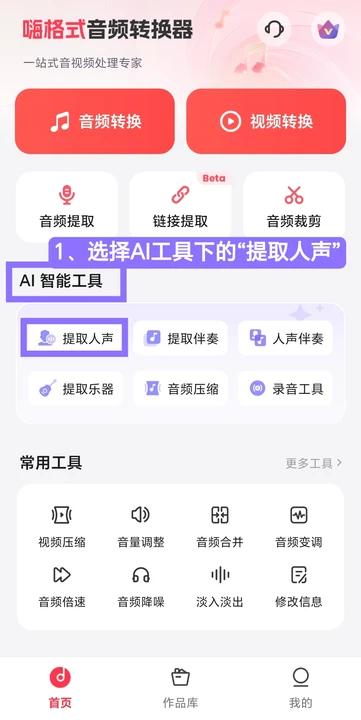
step 2.从音频库、下载库等渠道选择原曲文件,支持多选和全选,点击下一步
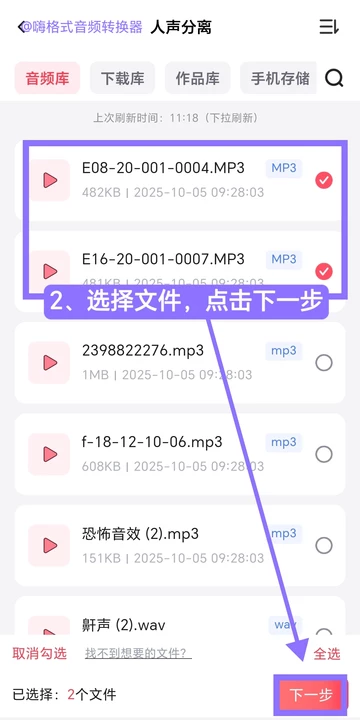
step 3.在提取内容中确认选择”提取人声”,根据上述模型说明选定对应模型,输出格式可选MP3或WAV,点击”开始提取”

step 4.处理完成后在首页下方的”作品库”查看,可直接试听、保存或转发
电脑端操作演示:
step 1.打开软件,点击首页”伴奏提取”功能
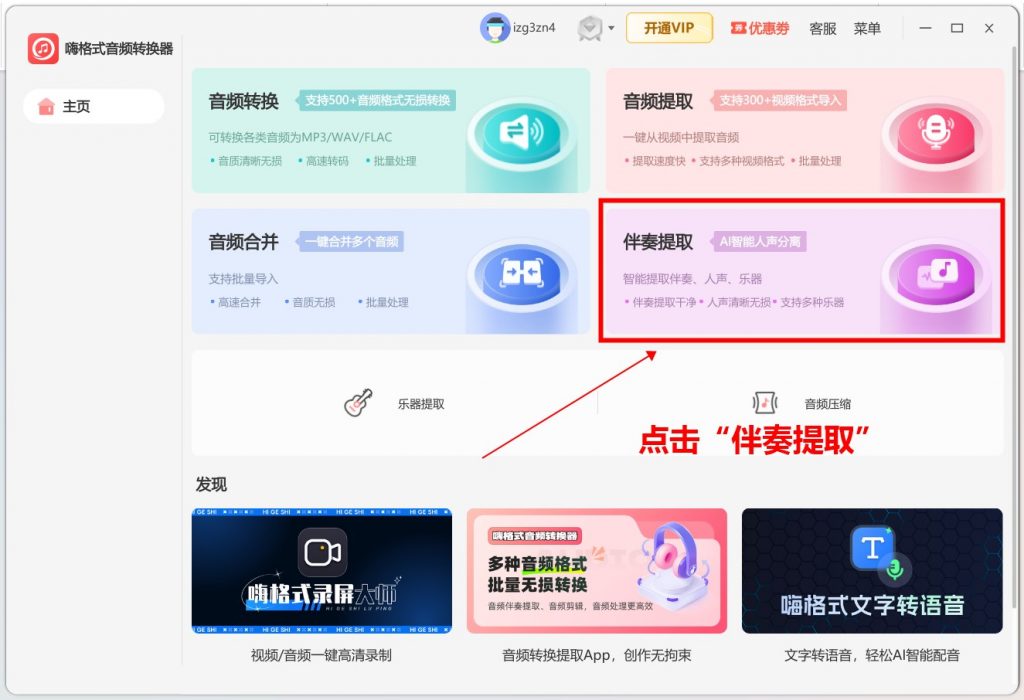
step 2.点击”添加文件”批量导入,支持一次性处理数十个音频文件。
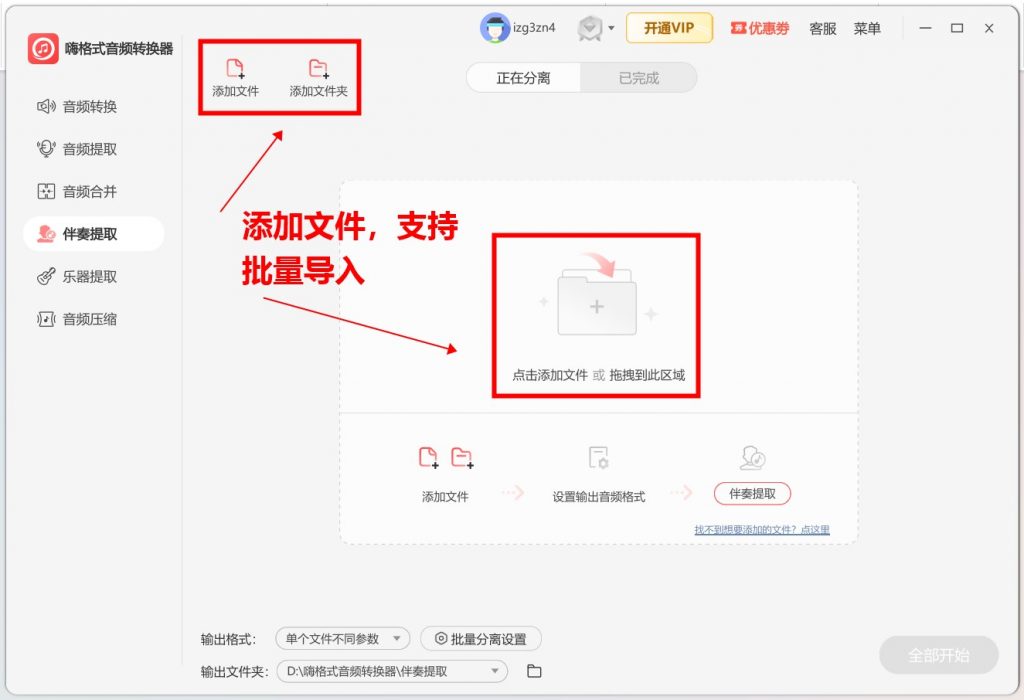
step 3.点击左下角”批量分离设置”,选择”人声提取”模式,设置输出格式和保存路径,点击”全部开始”自动排队处理
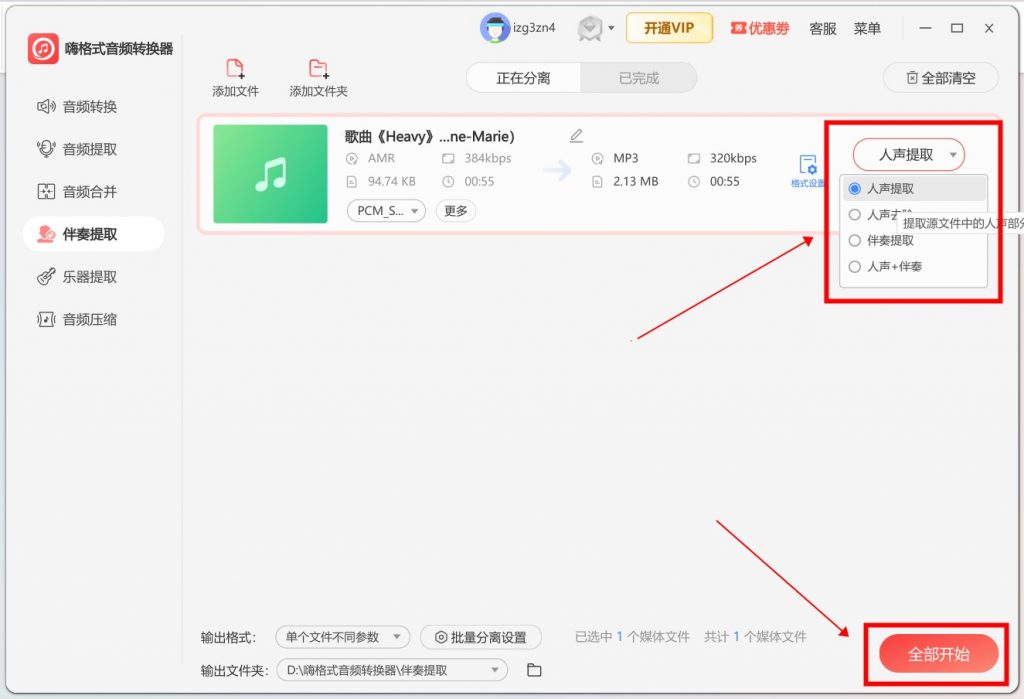
step 4.完成后在”已完成”界面查看
输出参数的专业建议:
| 参数 | 推荐设置 | 原因 |
| 音频格式 | WAV | 无损保留高频细节,避免MP3压缩导致的频谱损失 |
| 比特率 | 512kbps(高质量)或源文件原比特率 | 低于192kbps会明显损失气声和泛音 |
| 采样率 | 44100Hz或48000Hz | 覆盖人声音域(85Hz-1100Hz基频+泛音)绰绰有余 |
| 声道 | 双声道 | 保留立体声场的空间信息,单声道会让声音变”扁” |
| 音量 | 100%-120% | 适度提升补偿分离过程中的电平损失,超过150%会引入削波失真 |
特别注意事项: 如果提取的干声后续用于AI模型训练,切勿在分离阶段做任何”音频变调”或”音频倍速”处理。这些操作会改变音高和时值特征,导致模型学到错误的映射关系。变调请在RVC或AI生成平台的推理阶段完成。
方案二:本地技术流(适合进阶用户)
对分离质量有极致要求、且愿意投入学习成本的进阶用户,可以选择开源工具链方案。
推荐工具组合: MSST-WebUI + UVR5.6
标准流程: 先用MSST做高保真全人声提取,再用UVR5剔除和声残影
关键参数:
- 模型选择UVR5的Kim Vocal 2
- 启用Remove Backing Vocals去除和声
- 输出务必选WAV无损
硬件要求: 需NVIDIA GTX 1060以上显卡,处理3分钟歌曲约2-5分钟,有一定学习成本。
三、从干声到AI翻唱的完整实战
以用AI翻唱歌曲并替换为自己的音色为例,完整流程如下:
| 步骤 | 操作内容 | 关键要点 |
| 1. 获取原曲 | 通过正规渠道下载无损FLAC或高品质MP3(建议320kbps以上) | 源文件质量是上限,低质源文件无法通过后期补救 |
| 2. 提取人声 | 使用嗨格式音频转换器,首页”AI智能工具”→”提取人声”,选择模型三(质量高),输出格式选WAV,采样率44100Hz,双声道 | 此步骤质量直接决定最终翻唱像不像你 |
| 3. 提纯处理(可选) | 若干声中仍有轻微和声残留,可再用”音频降噪”功能轻度处理,调节声音至100%-120% | 轻度处理即可,过度降噪会损失自然人声质感 |
| 4. 剪辑对齐 | 使用”音频裁剪”功能,精确截取副歌部分(拖拽设置起止时间,保留选中部分),导出为WAV | 确保切片时长符合模型训练要求 |
| 5. 导入RVC训练 | 将处理好的干声切片放入RVC的datasets文件夹,按标准流程训练模型 | 遵循RVC官方训练指南的切片时长和命名规范 |
| 6. 推理生成 | 用训练好的模型推理目标歌曲,此时可配合”音频变调”功能(-12至+12,步进0.5)微调音高适配度 | 变调在推理阶段完成,不影响模型学习 |
四、核心原则:第一块多米诺骨牌
整个流程中,步骤2和3的质量直接决定了最终翻唱像不像你。如果分离阶段就丢了细节,后面再好的AI模型也补不回来。
2026年的AI音频工具已经强大到足以让非专业用户产出准专业级内容,但技术门槛的降低不等于审美标准的降低。干声提取是AI翻唱的第一块多米诺骨牌,倒得正不正,决定了后面所有牌的方向。
对于追求效率与质量平衡的用户,嗨格式音频转换器的AI智能分离方案提供了兼顾便捷性与专业度的选择。



