

视唱练耳训练中,一个长期被忽略的瓶颈在于素材本身。成品歌曲中人声、贝斯、鼓、键盘全部叠在一起,初学者被迫同时处理多个声部,相当于还没学会走就要跑。专业院校的分层训练法之所以有效,核心在于隔离单一元素——先练旋律,再练和声,最后综合。但现实中,无伴奏的流行歌人声素材很难找到,清唱版曲库有限,传统歌曲又缺乏吸引力。
AI人声分离技术的出现,恰好解决了这一矛盾。通过深度学习模型,任何流行歌都能提取出干净的人声旋律线,学生可以先用纯净人声练旋律听写,过关后再回听原曲分析和声与节奏。能力构建从并行处理变成串行递进,训练效率大幅提升。

一、传统消音方法为什么不够用
传统手段如EQ切高频或相位抵消,本质上是削弱伴奏而非真正分离人声。副作用非常明显:
- 人声泛音被切掉,导致音色干瘪
- 残留伴奏形成”鬼影”,干扰判断
- 音高完整性无法保证
- 视唱练耳对音准极其敏感,素材失真会让训练变成猜音游戏。
AI源分离基于深度学习模型,能智能识别频谱重叠区域的人声与伴奏成分,重建独立波形。提取的人声保持原始音高、音色和气声细节,这才是教学可用的素材。
二、制作扒带教材的完整流程
下面以制作一套旋律听写训练素材为例,介绍从选曲到训练落地的完整方案。
2.1 选曲原则
| 阶段 | 推荐曲目特征 | 示例 |
| 初学者 | 旋律线条清晰、音域在一个八度内、节奏以四分和八分音符为主 | 《月亮代表我的心》《送别》 |
| 进阶 | 转音复杂的R&B或爵士 | 视学生水平灵活选择 |
音源质量提示:尽量选择256kbps以上码率的音频文件,分离效果更干净。
2.2 工具选择要点
在挑选人声分离工具时,建议关注以下三个维度:
- 模型专业性:基于AI的源分离,而非简单的频段切割
- 音质无损:输出WAV格式,保留高频泛音
- 操作便捷:支持批量处理,无需复杂DAW操作
2.3 嗨格式音频转换器:从原曲到纯净人声
嗨格式音频转换器满足以上所有人声分离的要求,以下以这款工具为例,展示从导入原曲到获取纯净人声的具体操作。
手机端操作流程
Step 1 — 打开APP,进入「AI智能工具」板块,选择「提取人声」功能。
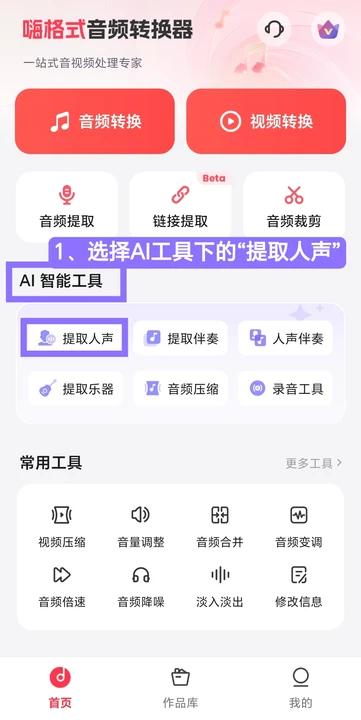
Step 2 — 从音频库或本地文件中选择原曲,支持多选和全选,点击下一步。
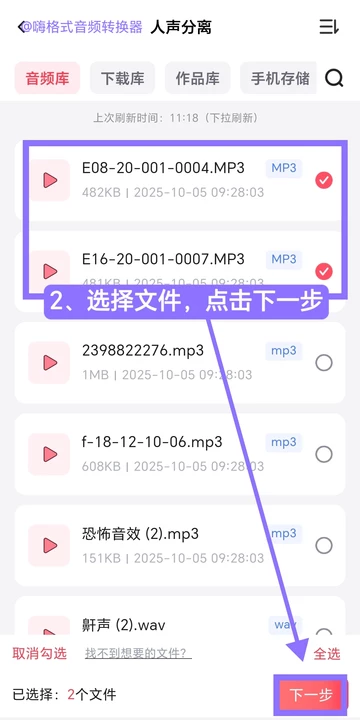
Step 3 — 在提取内容中确认选择「提取人声」。推荐选用针对人声频谱优化的模型(人声处理好、速度快),该模型对齿音和气声的处理更自然。输出格式可选MP3或WAV,点击「开始提取」。

Step 4 — 处理完成后,在「作品库」中查看结果,可直接试听、保存或转发。
电脑端操作流程
Step 1 — 打开软件,点击首页「伴奏提取」功能入口。
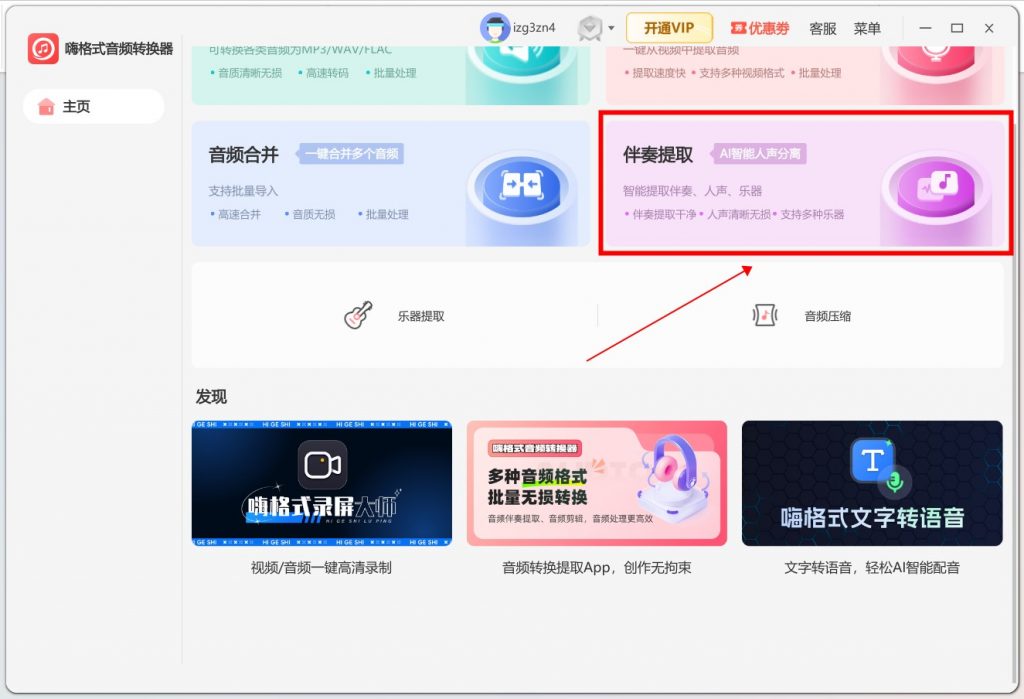
Step 2 — 选择文件,支持直接拖拽文件到指定区域,或者选择文件夹上传。
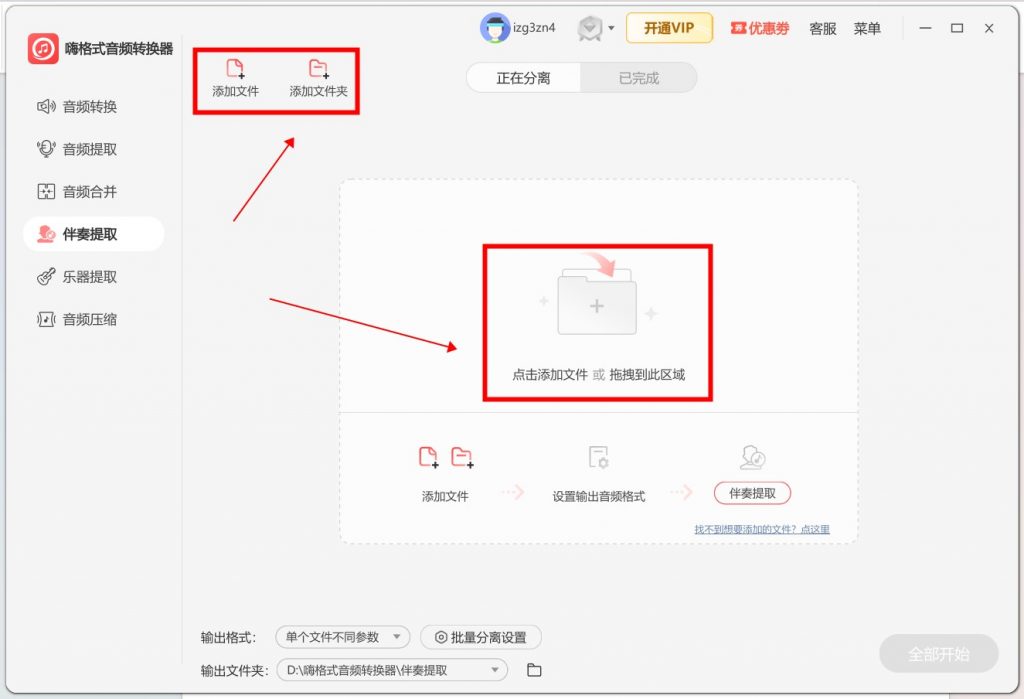
Step 3 — 输出格式选择「使用批量分离参数」,进入「批量分离设置」,选择「人声提取」模式。设置输出格式和保存路径,点击「全部开始」。
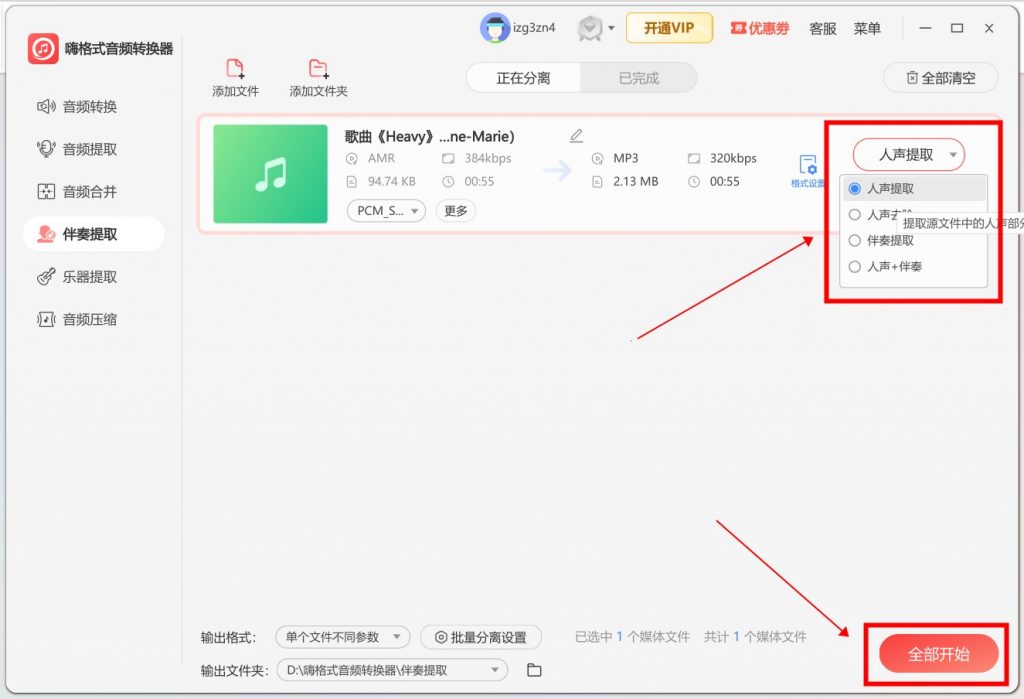
Step 4 — 处理完成后,在「已完成」界面查看提取结果。
教学应用建议
将提取的人声导入DAW(如Logic Pro、Cubase等),按主歌/副歌/桥段分段标记,设置循环播放。训练流程建议如下:
- 学生先听纯净人声,独立完成旋律听写
- 对照原曲,检查和声与伴奏编配
- 逐步增加难度,从单声部过渡到多声部
2.4 训练节奏设计
| 训练周期 | 时长 | 内容 |
| 每日 | 15-30分钟 | 从2小节短句开始 |
| 第1-2周 | — | 逐步增加到4小节、8小节 |
| 持续 | — | 旋律稳定后,将提取的人声与原曲伴奏重新组合,逐步加入和声维度 |
纠错方法:学生听写错误后,先唱一遍自己写的谱子,对比原曲自行找错。自我纠错比被动接受答案有效十倍。
三、进阶应用与关键细节
3.1 验证方法
学生扒完旋律后,可将提取的人声导入Melodyne等修音软件,直观对比所写谱子与实际音高,精准定位是音程判断错误还是节奏记错。
3.2 教材分级体系
批量提取多首歌的人声后,建议按难度分级制作题库:
- Level 1:四度以内音程的简单旋律
- Level 2:八度跳进
- Level 3:带变化音的转音
3.3 和声过渡策略
不要急于从纯人声跳到完整原曲。中间阶段可以:
- 只听人声 + 贝斯
- 只听人声 + 和弦
- 逐步适应多声部环境
四、写在最后
视唱练耳的本质,是耳朵、大脑和声音之间的反复对话。技术降低的是素材获取门槛,不是训练本身。把对话环境从嘈杂的混音变成干净的人声分轨,是很多学习者突破瓶颈的关键一步。
如果你正在自学扒带或带学生练耳,不妨尝试用嗨格式音频转换器的AI人声分离技术重构训练流程,让每一步都走得更扎实。



